
Allow me to introduce a remarkable project: Dharmamitra — https://dharmamitra.org/.
In my first post I wrote, “I suspect that even future AI models may not improve much in handling Classical Chinese, as it is a very niche need.” I was wrong. I did not anticipate how fast this model would improve.
When Dharmamitra shines
Used as a translation engine, Dharmamitra performs impressively on Classical Chinese → English when the target Buddhist scripture is narrative. In tests with story-centered sutras, the results are strong enough that someone unfamiliar with Buddhism can grasp over 90% of the meaning. That is a real and practical threshold: the plot flows, the characters are placed correctly, and the takeaways land for non-specialists.
Its strongest feature, though, is multi-text collation. When we have multilingual Buddhist sources that have already undergone careful scholarly collation, Dharmamitra’s English (research) mode can pinpoint each sentence or verse and lay out the corresponding originals and explanations across languages side by side. For research, this is gold: quick triangulation, faster verification, and a clearer map of textual relationships.
Dharmamitra can also orient itself when given Sanskrit-transliterated dhāraṇīs. If the string isn’t too short, it often identifies which esoteric system the dhāraṇīs likely belong to. However, it may not always locate the exact Chinese or Tibetan canonical locus—especially in cases where no Sanskrit original survives.
Where the edges still show
The cracks appear with early, terse, elliptical Classical Chinese. In these cases, Dharmamitra can fall into 望文生義—taking the surface form at face value without context—and it sometimes seems to apply an internal Traditional↔Simplified conversion that nudges it toward the wrong character.
A concrete example:
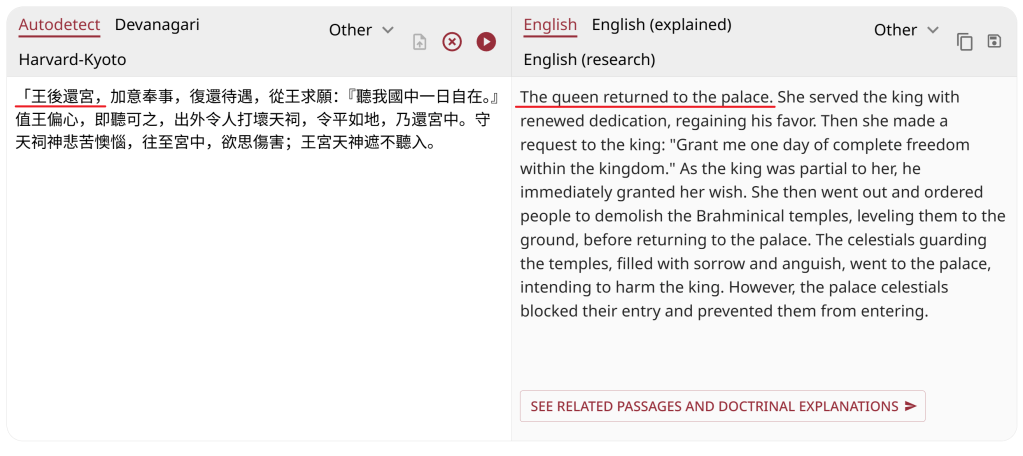
「王後還宮」
(Later, the king returned to the palace.)
Dharmamitra rendered this as: “The queen returned to the palace.”
This error only happens if one confuses 「後」 (behind, later, after) with 「后」 (sovereign, empress, queen).
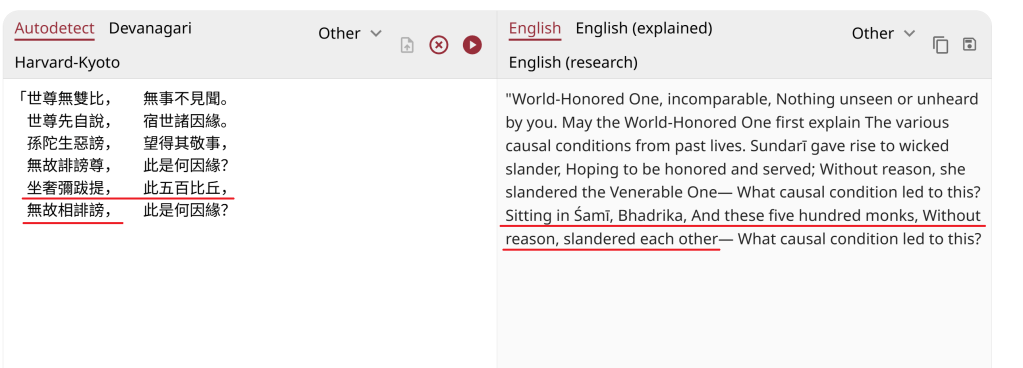
Another example involves grammar and agency. In one test passage, 「坐」 carries the passive/casualty sense of 「被」, and 「五百比丘」 is the subject. The event being described is that five hundred bhikṣus were groundlessly slandered by 奢彌跋提 (Śāmīvatī). Dharmamitra mixed this up—misreading who did what to whom—and the direction of the action flipped. These are the sorts of errors native speakers fix by context, but which are hard for a model unless it explicitly reasons across commentarial cues or parallels.
Like most LLM-based systems, Dharmamitra can hallucinate. If the input to be translated mixes languages—say, Chinese prose with Sanskrit or Tibetan transliterations for people and place names—it sometimes emits random, unrelated names. And when a passage or verse exists only in Chinese or Tibetan, the system occasionally overreaches, “expanding” the passage by associating it to a different, multilingual, collated text that looks similar but isn’t actually a source witness.
Finally, its references are not always accurate. For English Buddhist texts it hasn’t seen, Dharmamitra may map them to the correct Chinese counterpart, yet still misreport chapter or fascicle numbers. That’s fixable with better metadata and stricter citation logic, but worth noting for anyone relying on it for bibliographic precision.
You might want to use it this way
- For narratives: Treat Dharmamitra as a fast, high-recall first pass. You’ll get a fluent draft that captures most of the story. Then, spot-check named entities, pronouns, and discourse markers.
- For terse early texts: If you don’t have a solid foundation in classical Chinese, then pair it with parallel witnesses is essential. This is where its research mode pays off—use the collation view to discipline the model’s guesses.
- For dhāraṇī identification: Use it to orient to a system or ritual family, but confirm locus and wording against catalogs and canons. Don’t assume the model can leap from a phonetic string to the exact Taishō or Derge location.
- For mixed-language passages: Lock down proper names first. Provide consistent transliteration and, if possible, a mini glossary up front. This reduces the chance of the model inventing people or places.
- For references: Always verify fascicle and chapter against a catalog or the canons themselves.
Dharmamitra is a milestone in the digital humanities of Buddhist studies. It advances the state of practical tooling for Buddhist textual work. It is already good enough to accelerate understanding for non-specialists and to speed up collation-driven research for specialists and successfully bridges the gap between classic philology and modern computational tools, thereby enabling a new generation of work that remains faithful to the depth of the tradition while making the texts more accessible and analyzable than ever before. I (and anyone working in Buddhist textual translation, ancient languages or digital humanities) would highly applaud the vision and rigorous execution of this project.
